Spark at Getir and a Story of a Strange Bug
This blog post is a cross-post of the article originally published on Medium.
At Getir, all the decisions we make and the services we run heavily depend on data. To analyze and process this data, we have been using custom Python scripts since our early days. However as time has passed, and data has grown in volume, these scripts have been slower to respond to our needs. Data processing jobs, which we depend on to make decisions, that once only took minutes, started to take hours. They quickly became harder to maintain, because each of them was written with different paradigms as our understanding of optimization and quality changed over time.
That is why we decided to move to Spark. By making this change, we aimed to have an infrastructure and source/sink agnostic codebase which would help us transition into a more configurable analysis environment. This infrastructure will let us scale more efficiently and run data processing jobs in parallel, analyze and process cold stored backup files, write out to different types of storage (Redshift, Mongo databases, Avro files), process our data in real-time, and create well documented visual workflows. How Spark has helped us completely improve our analytics process is a story in and of itself. That story, however, is for another time.
This story is about a strange little bug, one that cost us a minor headache. We started moving our legacy scripts to Spark a month ago, and since we are in the process of moving to Redshift, some of our data that is generated by these scripts were still being written to MongoDB. So the first thought that popped into our heads was to write our Spark generated data to MongoDB as well, without disrupting our services that queried this data.
So there we were, implementing minor analyze jobs with Spark, and writing the output into MongoDB, to be backward compatible. Soon enough we noticed something was wrong.
Let’s say we have 2 models: Order and User
And we want to save a DataSet of orders, where each one refers to a single customer that the order belongs to. E.g. orders = [..., { ...otherFields, customer: ObjectId }] this data gets inserted into MongoDB successfully. Each Order document, gets a customer field with a type of ObjectId.
But, if we try to save a DataSet of customers, which has a one-to-many relationship to the aformentioned Order documents, with a field called orders. E.g. customers = [..., { ...otherFields, orders: ObjectId[] }], instead of an array of ObjectId’s in MongoDB, we got an array of Objects that had ids of the orders as a string in a field called $oid! So we got: { $oid: 'abc...' } instead of ObjectId('abc...')!
Being the well-behaving programmers we were the first thing that we thought of was the article “It’s Always Your Fault” by Jeff Atwood. Surely there couldn’t be a bug with writing DataSets to MongoDB. Did we do something wrong? However exhausting every thought we had, and searching all over the web, we couldn’t find any clues that showed that our code was flawed.
So down the rabbit hole, we went. The first stop was understanding how the DataSet was translated into a MongoDB collection. MongoDB Spark Connector does this. Given each row in your DataSet, it decides how to map it to a BsonDocument, and then writes the results into a MongoDB collection. When doing this operation, MongoDB types such as ObjectID are converted into structs for working with a DataSet. This explained the objects that we saw inside the MongoDB collection. So perhaps there was a bug that caused the objects inside of DataSet to not get converted back to Bson types?
With this understanding, we set out to reproduce our issue with as less code as possible. We wrote a small script that created a constant DataSet which had fields that contained ObjectId and wrote them to a local MongoDB.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
case class Order(id: String, userName: String)
val orders = Seq(Order("5b85bda7685ca053517a948b", "Ahmet"), Order("5b85bda764d8194a675a546d", "Mehmet"), Order("5b85bda812c1e568bc6596dc", "Ahmet")).toDS()
orders
.groupBy("userName")
.agg(
first(struct($"id" as "oid")) as "firstOrder",
collect_list(struct($"id" as "oid")) as "orders"
)
.write
.format("com.mongodb.spark.sql.DefaultSource")
.option("spark.mongodb.output.uri", "mongodb://localhost:27017/local.test")
.save()
Just as we suspected, this small script produced the same unexpected result. The structs inside the DataSet were not converted to Bson type when they were inside an array. The collection that was created by this script can be seen below:
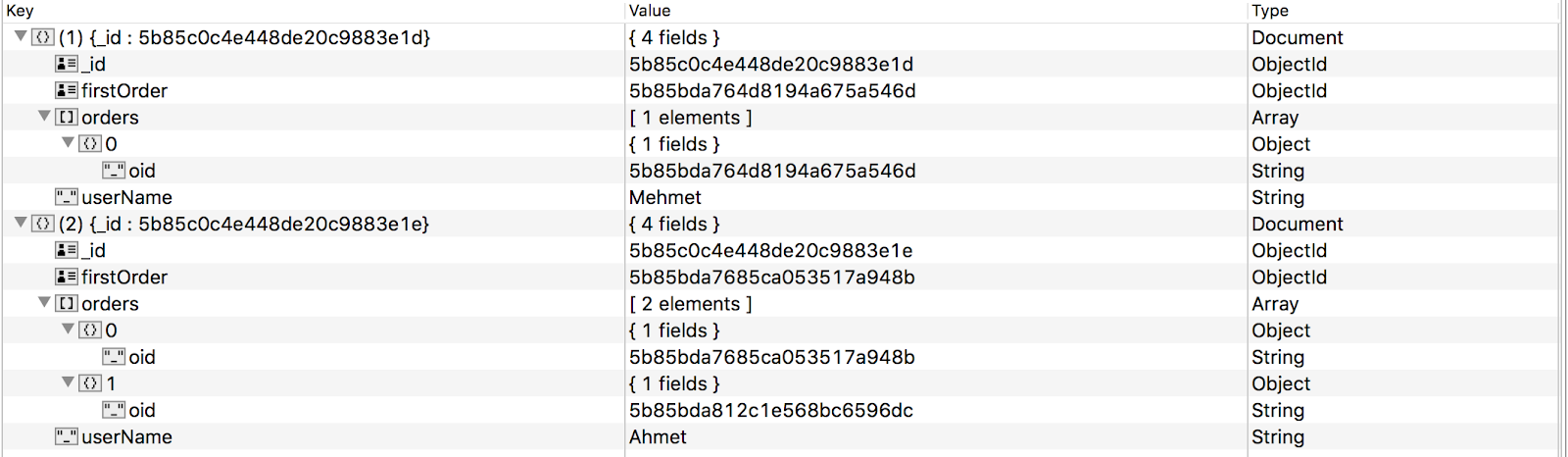
Even though the firstOrder field has the type of ObjectId, the orders field is an array of Objects instead of ObjectIds. Now we were sure that something was wrong with the connector. We started inspecting the connector source code, and soon enough we noticed that the recursive function that handled Array and Map types for the DataSet had two small bugs, that caused it to not convert the MongoDB types inside array or maps. We double checked our results and created a branch that worked as we expected.
After opening a Jira issue for the connector, we talked with the author about how to merge our fixes into the project and opened a PR for the fix.
Also when inspecting the code further, we noticed that the DataSet schema to BsonDocument conversion could be optimized further. The Scala code was doing the schema to Bson type inferring for each row, but since the DataSet schema is static for a given list of records, this could be a one time process to infer how to convert the DataSet rows into Bson types. So we did some changes. The code that explains this optimization is below:
// Previous approach to conversion
// definition
def rowToDocument(row: Row): BsonDocument
// usage
rowToDocument(row) // for each line
// The (micro) optimized approach
// definition
def rowToDocumentMapper(schema: StructType): (Row) => BsonDocument
// usage
val mapper = rowToDocumentMapper(dataSet.schema) // one time, before starting the row writing
mapper(row) // for each line
We made a POC for this in another branch and talked about the possibility of merging this into the connector with the author of MongoDB Spark Connector as well.
Both the bug fix and the optimization we did was merged into the MongoDB Spark Connector code. The changes were published with the 2.1.3, 2.2.4 and 2.3.0 versions of the connector. This time it was us that spotted the unicorn or the leprechaun with the pot full of gold. We hope we will be as lucky in the future. See you then.
Thanks to Ross Lawley, the author of MongoDB Spark Connector, for his quick response to our issue and his help in merging our changes into the connector.